
robots.txt file: The Ultimate Web Crawler Guide

There are many methods of enhancing SEO that isn’t difficult or time-consuming. One of them is efficient crawl of web or web spidering. Efficient web Crawlers achieve this with ease. And the robots file is one of them. You don’t have to have any technical knowledge to leverage the power of this txt file. If you can find the source code for your website, you can use this. One of the major goals of SEO is to get search engines to crawl your website easily so they can increase your rankings in SERP results.
This tiny text file is part of every website on the Internet, but most people don’t even know about it. It’s designed to use & work with search engines, but surprisingly, it’s a way to obtain SEO juice just waiting around to end up being unlocked. It do helps to improve the SEO of your website. It is a legitimate SEO hack that you can start using right away. It’s a way to increase your website SEO. And, It’s not difficult to implement either. It is also called as robots exclusion protocol or standard.
What is robots.txt?
It is a txt file that guides search engine web bots either to crawl or not to crawl certain pages or sections of a website. usually, search engine bots such as Google, Bing & Yahoo do recognize & respect directions of this file.
Is robots.txt file really important?
Now, let’s take a look at why the robots file is the necessary driving force for crawling a website.
The robots file is a text file that tells web robots (example search engines) which pages on your site to crawl. It also tells web robots which pages not to crawl too.
For example, A search engine is planning to visit a site. Before it visits the target page, it will check the robots.txt file for instructions of Web crawling. The search engine tries to locate a robots file in the domain home directory. An example of robots.txt file.
There are different types of robots txt files. So let’s look at a few different examples of what they look like.
Examples of robots file
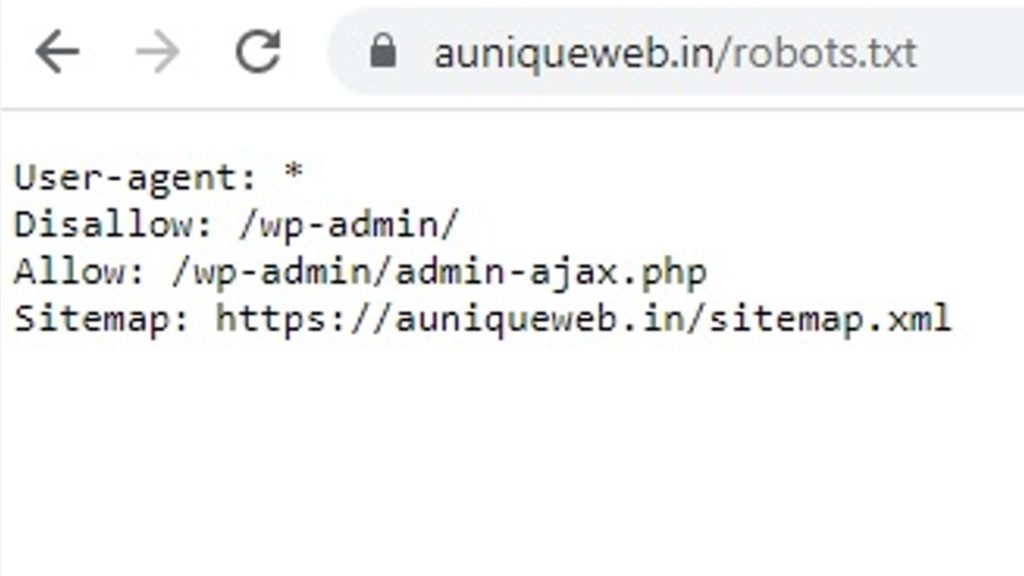
Below are actually the basic skeletons of a robots file.
Example 1:
User-agent: *
Disallow:
The asterisk after “user-agent” implies that it applies to all search engine robots that go to the site.
The no slash after “Disallow” tells the robot to visit each & every page on the site.
Example 2
Here is another basic skeleton of a robots file.
User-agent: *
Disallow: /
The asterisk after “user-agent” implies that the robots txt applies to all internet web robots that visit the website.
The slash after “Disallow” tells the robot not to visit any pages on the site.
Now, let’s come back to robots file.
You probably have a whole lot of pages on your own website, right?. Even if you don’t think you do, go & check it. You might be surprised to see a lot of links to the website. If a search engine or web crawler crawls your site, it will crawl every page of the website. And for those websites who have a lot of web pages, it will require the internet search engine bot some time to crawl them. That may have negative effects on your website ranking.
It is because Googlebot (Google’s search engine bot) has a “crawl budget.” for each & every website.
Googlebot’s Web Crawler budget breaks down into two parts.
1. The first is crawl rate limit
2. The second part is the crawl demand.
Here’s how Google explains about Crawl Rate & Crawl Demand
Fundamentally, the crawl budget is “the number of URLs Googlebot can and really wants to crawl.”
So, You need to help Googlebot spend its web crawler budget on your site in the simplest way possible. In other words, it should be by crawling your most valuable pages of the website.
According to Google, There are certain factors that will “negatively affect a site’s crawling and indexing.”
Here are those factors affecting crawl budget
So let’s come back to robots txt.
If you create the proper robots file, you can tell internet search engine bots (ex Googlebot) in order to avoid certain webpages of the website. Take into account the implications. Let’s assume you tell internet search engine bots or web crawlers to just crawl your most readily useful articles. Then, the web bots will crawl and index your website as per the instruction of it. It must be based on that content alone.
See what Google says in this regard:
“If You don’t want your web server to be overwhelmed by Google’s crawler or to waste search engine bot’s crawl budget crawling unimportant pages or similar unnecessary pages on your site.”
Through the use of your robots txt the proper way, you can tell internet search engine bots to spend their web crawl budgets very wisely. And that’s the reason the robots file is so useful within the context of SEO.
What is the way to locate your website’s robots file?
Are you interested to look at your robots file?. There’s a super-easy way to view it.
All you have to do is type the basic URL of the site into your browser’s search bar (e.g., https://auniqueweb.in, etc.). Then add /robots.txt to the end of the above URL. ie https://auniqueweb.in/robots.txt.
Further, this method will work for any site. So you can peek on other sites’ files and see what they’re doing in robots file.
While doing it, you may witness one of three situations :
1) You may find a robots file.
2) You may find an empty file. For example, the Disney website does not contain a robots file.
3) You may get a 404. It means that accessing the URL returns a 404 for robots text file.
Now, let’s do a review of your own website’s robots text file. If you find an empty file or a 404 error while accessing it, you may fix that as per your wish. If you do find a valid file, it’s probably set to default settings that were created when you made your website. The same approach may be used to look at other sites’ robots text files.
Note: If you’re using WordPress, you might see a robots text file when you go to yourwebsite.com/robots.txt. The reason being WordPress creates a virtual robots text file if there is no robots text in the domain root directory.
If you don’t find a robots text file in the domain’s root directory, Then, you will need to create one from scratch.
Tools to create robots text file of a website from scratch
Now, let’s look at actually changing your robots text file or creating one from scratch.
To create a new robots text file, Always open a plain text editor like Notepad (Windows) or TextEdit (Mac).
If you have a robots text file, you’ll need to locate it in your Domain’s root directory. Usually, you can find your root directory by going to your hosting account website, logging in, and heading to the file management or FTP section of your site.
You should see something that looks like this:
Find your website robots text file in the domain’s root directory. Now, open it for editing. Also, Delete all of the text, but keep the file as it is.
Creating a robots text file
As said earlier, You can create a new robots text file by using the plain text editor of your choice. Remember, only use a plain text editor. If your website already has a robots text file, make sure you have deleted the text of file (but not the file itself).
First, It is better to become familiar with some of the syntax used in a robots text file.
Google has a very nice explanation of some basic terms of robots text file
Let’s start by setting the following term “user-agent” . It is going to set it so that it is applicable to all web robots. Do this by placing an asterisk after the term user-agent, like this:
user-agent: *
In the next line, type “Disallow:” But, don’t type anything next to it.
Since there’s nothing following the disallow, internet robots will be directed to crawl your website completely. At this time, everything on your own site is a fair game for all crawlers.
So far, your website’s robots text file must look like the below code.
User-agent: *
Disallow:
The above two lines actually helping crawlers doing a lot of work.
Further, Believe it or not, This is what a basic robots text file looks like. Now, let’s take it to another level and make this little txt file into an SEO booster.
How to link your XML sitemap to robots text file?
Please note it’s not necessary. If you want to, here’s what to type in robots text file
sitemap: https://auniqueweb.in/robots.txt
Optimizing robots text file for SEO
Optimization of robots text file depends on the content you have on your website. There are many ways to use robots.txt file to your advantage.
Please Keep in mind that you should not use robots text to block pages from search engines.
Here are the most common ways to use robots text file. They are
1. Maximize search engines crawl budgets by telling them not to crawl the parts of your site that aren’t displayed to the public. It is One of the best uses of the robots text file.
For example, if you visit the robots text file of auniqueweb.in, you’ll see that it disallows certain file paths (wp-admin) for crawling.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Since this page is just used for logging into the backend of the site. It wouldn’t make sense for search engine bots to waste their time crawling unnecessary stuff on this page.
2. You may use an identical directive (or command) for web crawlers to avoid crawling specific webpages of the website. After the disallow, enter the part of the URL that comes after the .in or .com, etc. Put that between two forward slashes.
So if you want to tell a web crawler not to crawl your page “Prohibited Page” ie , you can place it like this in robots text file:
Disallow: /Prohibited-Page/
Types of pages to exclude from indexation
Since there are no universal rules for which pages to disallow indexation, your robots text file will be unique to your website. Use it as per your wish & make sure it is acceptable by google’s robots testing tool. Then You might be wondering specifically what types of pages to exclude from indexation.
Here are a couple of common scenarios where it is need of the hour.
1. Purposeful duplicate content.
While duplicate content is mostly a bad thing, there are a handful of cases in which it’s necessary and acceptable.
For example, if you have a printer-friendly version of a page, you technically have duplicate content. In this case, you could tell web bots to not crawl one of those versions (typically, the printer-friendly version of the page).
Another example is Split-testing pages that have the same content but different designs. This is also a well-known scenario from excluding from indexation of google’s SERP.
2. Thank You Pages.
The thank you page is one of the marketer’s favorite page because it means a new lead.
Allowing access to thank you pages through Google is a bad practice. You can disable it by blocking your thank you page. Therefore, you must make sure only qualified leads are seeing them.
For example, the thank you page is at . In your robots text file, blocking that page would look like this:
Disallow: /thankyou/
But, Using disallow directive doesn’t actually prevent the page from being indexed by google. So theoretically, you could disallow a page, but it could still end up in the index by the google & Generally, you don’t want that. right?
Two directives noindex, nofollow of robots text file
There are two directives you should know: noindex and nofollow.
noindex directive
That’s why you need to use the noindex directive. It works with the disallow directive to make sure bots don’t visit or index certain pages of websites as per instructions in robots text file.
For example, If your website has a page that you don’t wish indexed (aka thank you pages), you may use both disallow and noindex directives:
Disallow: /Prohibited-Page/
Noindex: /Prohibited-Page/
Now, that page won’t show up in the SERPs.
nofollow directive
Now, Let’s look into the nofollow directive.
This is identical to a nofollow link. In short, it tells web robots not to crawl the links on a page.
However, the nofollow directive will be implemented a bit differently because it is actually not part of the robots text file. Nevertheless, the nofollow directive continues to be instructing web robots, therefore it’s the same concept. The only difference is where it actually takes place.
Find the source code of the page you want to change, and make sure you’re in between the <head> tags.
Then paste this line:
<meta name=”robots” content=”nofollow”>
So it should look like below:
<head>
<meta name=”robots” content=”nofollow”>
</head>
If you want to add both noindex and nofollow directives to page, use below line of code between <head> tags.
<meta name=”robots” content=”noindex,nofollow”>
This will give web robots both directives at once.
Now, Lets Test It Thoroughly
Finally, test your robots text file to make sure everything is valid and operating the right way mentioned by Google.
As part of the Webmaster tools, Google has been providing a free robots text tester for testing robots text file.
Here is the process to test the robots text file.
First, sign in to your Webmasters account or Google Search Console by clicking “Sign In” on the top right corner.
Select appropriate property (i.e., your website) and click on “Crawl” located in the left-hand sidebar of web page
You’ll see “robots text Tester” Click on that.
If there’s any code already in the box, delete it and replace it with your new robots txt file.
Now, Click “Test” located on the lower right section of the screen.
If the “Test” text changes to “Allowed”, which means your robots text file is valid.
Finally, upload your robots text to your domain’s root directory (or over-write file there if you already had one). You’re now armed with a tiny but powerful file, and you should see an increase in your search visibility definitely.
My website does not have robots.txt file. Does it really needed it?
No, It is not needed. When a Googlebot visits a web site, it first ask permission to crawl. It does this by attempting to retrieve the robots.txt file in your domain. A web site without a robots txt file, robots meta tags, or X-Robots-Tag HTTP headers are usually crawled and indexed as usual.
How many methods available to block web crawlers?
There are 3 different types of methods available to block web crawlers.
Which method to use to block web crawlers?
It depends on your wish to use a method as per convenience. In fact, there are a few good reasons to use any one of the method mentioned below.
What are those 3 methods available to block web crawlers?
robots.txt
Use robots.txt file if crawling of your content has been causing issues on your servers. For instance, you may wanna to disallow crawling of infinite scrolling scripts. Also, Note that Don’t try to use the robots.txt file to block private content. Block Private Content either by using server-side authentication or handle canonicalization. To make sure that a URL is not indexed, always do use the robots meta tag or X-Robots-Tag HTTP header instead.
robots meta tag
Use it if you wanna control how an individual HTML webpage is shown in google search results or to make sure that it is not shown in google search results.
X-Robots-Tag HTTP header
Use it if you need to control how content is shown in google search results or to make sure that it is not shown in google search results.
May I use robots.txt, robots meta tag, or the X-Robots-Tag HTTP header to remove any website i choose from Google Search Results?
Can these methods used to remove any website i choose from Google Search Results?
No, You cann’t. The methods described above are only applicable to websites where you may modify the code or add files as per your wish.
Is it possible to slowdown Google’s crawling speed of my website?
Yes, it is possible to slow down Google’s crawling of my web site. To do it, please do follow the below process.
In your Google Search Console account, You may adjust the settings of crawl rate as per your requirement.
May I use the same robots.txt file for multiple websites?
Can I use a full URL of robots.txt file of a website in another website instead of a relative path?
No, you can not use full url of robots.txt file of a website in another domain/website. The directives mentioned in a robots.txt file (with an exception of sitemap:) are only valid for relative paths of a website.
Is it allowed to place robots.txt file in a subdirectory?
No. The robots.txt file always be placed in the top most directory of the web site.
Is it possible to prevent others not to read my robots.txt file?
No. It is not possible to prevent others not to read my robots.txt file. The robots.txt file is accessible to various kinds of users. For instance, either folders or file names of content are not meant for the public use, please do not list them in the robots txt file. Further, It is also not recommended to serve different robots.txt files for different user agents or other attributes.
Is it require to include an allow directive to allow crawling?
No, To allow crawling, You do not need to include an allow directive. All the URLs are implicitly allowed. And, the allow directive is used to override only disallow directives in the same robots.txt file.
What happens if i used an unsupported directive in my robots.txt file?
Usually, in worst case scenario, the incorrect / unsupported directives will be ignored.
What happens if there is a mistake in my robots.txt file?
Usually, Web crawlers are very flexible. It typically will not be swayed by minor mistakes of robots.txt file. In case you noticed mistakes in it, when you fetched robots.txt file, do try to fix it as it is easy to fix & you are aware of problems in your robots file.
What is the difference between google bots vs humans who fetched robots.txt file?
As you know, Google can’t read minds when interpreting a robots.txt file, however, a human can interpret the robots.txt file he fetched.
What software should I use for creating a robots.txt file?
You can use any software/Application/program that creates a valid text file. Most Common programs used to create robots.txt files are Notepad+, TextEdit, vi, or emacs. Do create a robots.txt file,. After creating your robots.txt file, validate it using the robots.txt validator/tester.
Can I make a webpage disappear from goggle search results by using a robots.txt disallow directive?
Yes, By Blocking Google from crawling a web page, it is possible to remove the webpage from Google’s index too. However, it does not guarantee that a web page will not appear in google search results.
In spite of it, Google may decide depending on external information such as incoming links. relevance and show the web URL in the google search results.
No, This file has no replacement in any of meta tags available as of date.
Does robots.txt & robots meta tag do the same work?
No. The robots meta tag controls whether a page is indexed or not. Whereas, the robots.txt file helps to control webpages which are accessible via web crawler.
However, to see this tag the webpage needs to be crawled. If crawling of a webpage is difficult/problematic (for instance, if the webpage causes a high load on the application server), do use the robots.txt file. Do Use the robots meta tag only to decide whether or not a webpage is shown in search results. Robots meta tag can be used for this task.
Would the robots meta tag be used to block a part of a web page from being indexed?
No, the robots meta tag be can not be used to block a part of a web page from being indexed. Please note that robots meta tag is a page level setting.
Is it allowed to use the robots meta tag outside of a section?
No, It is not allowed to use the robots meta tag outside of a section. It is always needs to be in the section of a web page.
Does the robots meta tag disallow crawling?
No. For instance, robots meta tag is mentioned with noindex. Still the web page needs to be recrawled periodically to check if the value of meta tag has been changed or not.
What is the difference between nofollow robots meta tag vs the rel=”nofollow” link attribute?
The nofollow robots meta tag is applicable to all links on a webpage. Whereas, The rel=”nofollow” link attribute only applicable to specific web links on a web page.
How To check the X-Robots-Tag of a URL?
A simple way to view the server headers is by using the URL Inspection Tool feature of Google Search Console.
To check the response headers of any web URL, do search for “server header checker”.
How to explicitly block a webpage from being indexed?
To explicitly block a webpage from being indexed, You may either use the noindex robots meta tag or X-Robots-Tag HTTP header. Further, please don’t disallow the web page in robots.txt. It helps the webpage to be crawled in order for the tag to be seen and obeyed as per the directive.
How long will it take for changes of my robots.txt file to affect on Google Search Results?
First, Do make sure that the cache of the robots.txt file is refreshed. Usually, threshold time to cache the contents is up to one day. You may speed up this process by submitting updated robots.txt file to Google.
In spite of finding the updated robots.txt file, crawling and indexing at times may take quite some time for the individual URLs. so it is not possible to give an exact timeline.
Also, please note that even if your robots.txt file disallowed access to a URL, the same URL may remain visible in google search results. It may happen despite the fact that we can’t crawl it.
Is there any way to expedite the removal of the webpage I wished to to blocked in Google?
Yes, There is a way to expedite the removal of the web pages. To expedite the removal of the web pages that you’ve blocked from Google, please always submit a removal request to the google.
How to temporarily suspend all crawling activity on my website?
Yes, You may temporarily suspend complete crawling of your website just by returning a 503 (service unavailable) HTTP status code for all URLs of website. It also includes the robots.txt file. Periodically, The robots text file will be retried until it can be accessed again. Also, It is not recommend to change your robots.txt file to disallow crawling.
How to disallow crawling of some of folders completely if my server is not case-sensitive?
Please do note that the Directives of the robots.txt file are all case sensitive.
As server is not case sensitive, it is always recommended that only one version of the URL is indexed by using canonicalization method. By Doing this, you will have fewer lines of code in your robots text file. As it is fewer lines of code, it will be easier for you to manage it too.
But If this isn’t possible in this scenario, it is recommended that you follow either of the methods mentioned below
a) list out the following the common combinations of the folder names,
or b) try to shorten it as much as possible, using only the first few characters instead of the full name.
For this example, instead of listing all upper and lower-case permutations of /ThisIsMyPrivateFolder, you could list the permutations of “/ThisIsMyP” (if you are certain that no other, crawlable URLs exist with those first characters). Alternately, it may also make sense to use either a robots meta tag or X-Robots-Tag HTTP header instead, if the crawling is not an issue.
Why is my website still being crawled in spite of returning 403 Forbidden HTTP Error for all URLs including the robots.txt file?
The HTTP status code such as 403 Forbidden is interpreted as the robots.txt file doesn’t exist. It means that crawlers will likely assume that all URLs of the website can be crawled. It is applicable to all other 4xx HTTP status codes too.
How to block crawling of the website?
To block crawling of the website, the robots txt file must return a 200 OK HTTP status code. Further, It must contain an appropriate disallow rule too.
Is Robots.txt file an exclusion protocol for web crawlers?
Yes, Robots.txt file is an exclusion protocol of web crawlers( aka Robots exclusion standard). It helps to ignore certain web pages, folders or files on a website.
Does it improve search engine optimization?
yes, Robots txt file is also used to improve search engine optimization.
Describe More About Robots.txt file?
Robots.txt is a plan text file that lets search engine spiders know what webpages or sections of a website not to crawl as part of crawling budget. It is very important to set up it correctly. At times a single mistake may get an entire web site de-indexed from search engines.
Can I Prevent Indexing Multimedia Resources, or Block Non Public Resources?
Yes, The robots exclusion standard may be used to prevent indexing multimedia resources (e.g. images, videos), block webpages that are not public (e.g. member login pages). And, also help to maximize the crawl budget.
What is the basic format for the robots.txt file?
The basic format for the robots.txt file is given below for your reference.
User-agent: ______
Disallow: ______
Where user-agent is the name of the robot that is being addressed,
“disallow” contain the name of the web page, a folder or a file that the robot must ignore while visiting your web site.
An asterisk (*) may be used instead of the name of a specific bot, if you want to address all kinds of the robots that may visit the web site.
How to describe robots.txt file where the crawlers are informed not to enter the tmp & junk directories?
User-agent: *
Disallow: /tmp/
Disallow: /junk/
How to inform the crawlers that a specific file should be ignored?
Here is the way crawlers are informed to avoid a specific file.
User-agent: *
Disallow: /directory_name/file_name.html
How is Robots.txt Important?
Robots.txt file is an important part of SEO. All major search engines do recognize it and obey this exclusion protocol.
The majority of websites may not be need this exclusion protocol. For instance, Google will only index the important webpages of a website, thus leaving out the the unnecessary web pages (e.g. duplicate pages).
However, but in some specific cases it is recommended to use robots.txt file.
What are the ways to create a robots.txt?
There are many different ways to create a robots.txt file.
You can create it from your
a) Using feature of Content Management System (CMS)
b) Using a plugin of Content Management System (CMS)
c) Creating a robots.txt on your computer using notepad
What are the reason to create a robots.txt file using a notepad?
The possible reasons to create a robots.txt file using a notepad are given below. They are
a) If you are not using a CMS
b) The CMS does not support creating a robots.txt file
How to create a robots.txt on your computer using notepad?
Here are the steps to create a robots.txt by yourself and manually upload it to your web server.
1. Open an editor software like Notepad on Windows OS or textEdit on Mac OS
2. Do Create a new file.
3. Copy paste one of the example of robots.txt files you have.
4. Adjust the code as per your requirement.
5. Save it with the filename as robots.txt file.
6. Upload it to your server in your website’s root directory.
Can Content Management Systems (CMS) helps to create robots.txt file?
Yes, a robots.txt file can be created using your Content Management System.
Usually, modern Content Management Systems (CMS) do have functionality to create and maintain robots.txt file. This feature will be included within the CMS itself.
How to create robots.txt using Yoast SEO plugin?
Here are the steps for The Yoast SEO plugin to create and maintaining the robots.txt file. They are
1. Log into your WordPress dashboard using wp-admin
2. Locate Yoast SEO plugin In the sidebar of WordPress dashboard.
3. Click on Tools of Yoast SEO plugin
4. Go to File editor to create & save Robots.txt file
How to create robots.txt using Rank Math plugin?
Here are the steps to create and maintain the robots.txt file in Rank Math SEO plugin:
1. First Login to your WordPress dashboard using your credentials.
2. In the sidebar of WordPress of dashboard , go to Rank Math > General Settings.
3. Go to Edit robots.txt to update & save the file.
Conclusion
Using robots text can make a significant difference in SEO of the website. By setting up your robots text file the right way, you’re not just enhancing your own SEO. You’re also helping out your visitors. If search engine bots can spend their crawl budgets wisely, they’ll organize and display your content in the SERPs in the best way. It means your website will be more visible in google search results.
Further, It’s mostly a one-time setup. It does not take a lot of effort to create your robots text file. And you can make little changes as your website needed. I reckon that gives a spin if you haven’t done setup robots text file before. Also, This post discussed how to find and use it, setting up a simple robot.txt file, and further learned about how to customize it for SEO.

Super !!

